2024-05-02 Hacker News Top Stories #
一句话摘要 #
- Printing Music with CSS Grid 文章探讨了如何使用CSS Grid技术在网页上打印乐谱,解决了音乐符号在网页上的排版问题。
- Kolmogorov-Arnold Networks 介绍了一种新型神经网络Kolmogorov-Arnold Networks(KANs),它基于强大的数学基础,可能成为多层感知器(MLPs)的有力替代品。
- Ask HN: Who is hiring? 这是一个关于2024年5月招聘信息的帖子,列出了不同公司的招聘职位、工作地点和工作性质。
- Better and Faster Large Language Models via Multi-Token Prediction 文献提出了一种改进的大型语言模型训练方法,通过多令牌预测提高样本效率和模型性能。
- Figma OSS Alternative Penpot是一款开源免费的设计软件,旨在连接设计师和开发人员,实现无需繁琐交接流程的协作。
- Car manufacturers break promise about sharing location data with police 美国参议员要求联邦贸易委员会调查汽车制造商违反保护客户位置数据的承诺。
- New findings point to an Earth-like environment on ancient Mars 研究团队在火星盖尔陨石坑内的湖床岩石中发现了高锰含量,表明这些沉积物可能是在古代河流、三角洲或湖泊岸边形成的。
- StoryDiffusion: Long-range image and video generation StoryDiffusion是一种用于长距离图像和视频生成的方法,通过一致的自注意力机制实现连贯的叙事。
- The Rabbit R1 is probably running Android and is powered by an Android app Rabbit R1是一款AI动力的手持设备,可能在内部运行Android系统,并由一个Android应用程序提供支持。
- Run llama3 locally with 1M token context 介绍了LLama-3梯度模型,该模型将LLama-3 8B的上下文长度扩展到超过1M个标记,使用户能够本地运行具有更大上下文的模型。
Printing Music with CSS Grid #
https://cruncher.ch/blog/printing-music-with-css-grid/
本文讨论了如何使用 CSS Grid 打印音乐谱,并探讨了将音乐符号在网页上呈现的方法。

作者提到了之前他创建的名为 Scribe 的音乐渲染器原型,以及如何利用 CSS Grid 来解决音乐排版中的布局问题。文章首先介绍了如何定义音符的排列和音高,使用 CSS Grid 中的类.stave 和.bar 来实现。作者展示了如何通过 CSS 属性和 data 属性将音符和拍子与网格对应起来,实现音符和拍子的正确排列。
另外,文章还提到了如何处理节拍之间的距离和符号之间的间隔,以及如何在网格中添加和排列和弦、歌词等元素。通过灵活运用 CSS Grid,作者展示了在网页上打印音乐谱的可能性,使得音乐符号可以像文本一样流畅和响应地呈现在网页上。
HN 评论 76 comments | 作者:speckx | 1 day ago #
https://news.ycombinator.com/item?id=40216057
-
- 评论者认为使用 CSS Grid 打印音乐是一项令人印象深刻的技术创新,适合轻量级项目,但对于复杂的完整乐谱可能不够精细。
-
- 有评论者认为 CSS Grid 在处理音乐排版时存在问题,如横杠、连线和节拍等,建议使用 SVG 或 Canvas 绘图。
-
- 评论中提到其他工具如 Soundslice 和 Sibelius Cloud Publishing 可用于在浏览器中进行可伸缩的音乐排版。
-
- 有人提到音乐排版师的专业性,以及使用 Lilypond 等工具进行复杂音乐排版的重要性。
-
- 评论者分享了对音乐排版的独特见解,认为 CSS Grid 在某些情况下是一种轻量级且实用的解决方案。
Kolmogorov-Arnold Networks #
https://github.com/KindXiaoming/pykan
本文介绍了 Kolmogorov-Arnold Networks(KANs),这是一种有着强大数学基础的神经网络,被认为是多层感知器(MLPs)的有力替代品。MLPs 基于通用逼近定理,而 KANs 基于 Kolmogorov-Arnold 表示定理。KANs 和 MLPs 是对偶的关系:KANs 在边缘上有激活函数,而 MLPs 在节点上有激活函数。这一简单改变使得 KANs 在模型精度和可解释性方面都比 MLPs 更好(有时甚至更好!)。
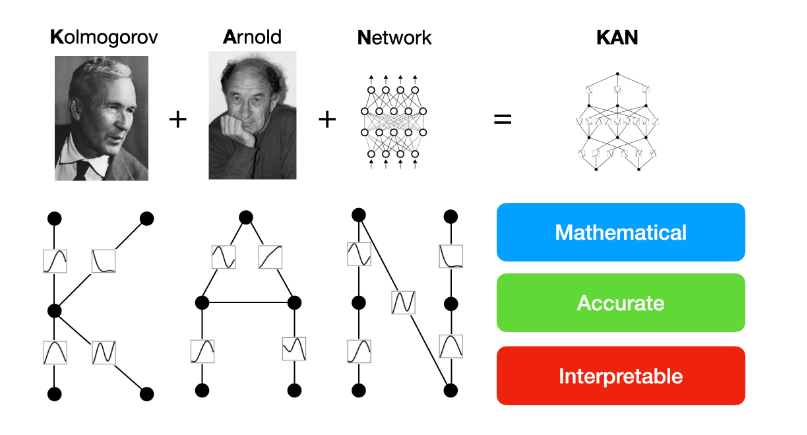
在精度方面,KANs 比 MLPs 具有更快的扩展能力,同时在参数更少的情况下具有更好的精度。例如,在拟合符号公式、特殊函数、解 PDE 以及避免灾难性遗忘等方面,KANs 都表现优异。
在可解释性方面,KANs 可以直观地可视化,并提供 MLPs 无法提供的解释性和互动性。我们可以使用 KANs 来潜在地发现新的科学定律,例如发现符号公式、数学上的结的定律、物理上的 Anderson 定域定律,以及三层 KAN 的训练等。
安装 pykan 有两种方式,通过 pypi 或 github,同时需满足一定的软件依赖。计算需求方面,教程中的示例通常在单个 CPU 上运行不到 10 分钟,而在单个 CPU 上可在一天内运行完所有论文中的示例。对于 PDE 的 KAN 训练成本最高,可能需要数小时到数天才能完成。文档链接在此,教程包括快速入门和更多演示,可以在 notebooks 中找到。
最后,作者提供了论文引用方式,同时欢迎通过 zmliu@mit.edumailto:zmliu@mit.edu 联系提出任何问题。
HN 评论 81 comments | 作者:sumo43 | 21 hours ago #
https://news.ycombinator.com/item?id=40219205
这篇帖子中的评论观点归纳如下:
-
- 有关 Kolmogorov-Arnold Networks 的 Pytorch Layer 实现,简化了核心代码,可能比原文更易收敛但操作较少;
-
- 有关该类模型在 GPU 上的友好程度,指出其不太友好,需要优化操作以提高效率;
-
- 评论者对实现简单的方法表示赞赏,认为简单的求和和乘积操作可以取得出乎意料的进展;
-
- 有关使用 Jupyter notebooks 进行实验的经验分享,提到了训练过程中的挑战和调整;
-
- 讨论了 KANs 与 MLP 的区别和优势,以及对新型架构的探讨和疑问;
-
- 有关 KANs 的训练和反向传播机制,以及对其潜在问题的担忧;
-
- 讨论了 KANs 的应用前景和可能性,以及与其他模型的比较和发展方向。
Ask HN: Who is hiring? #
https://news.ycombinator.com/item?id=40224213
这是一个针对 2024 年 5 月招聘信息的 “Ask HN: Who is hiring?” 帖子,主要内容是各公司招聘信息。
帖子中列出了一些公司以及它们的招聘职位、工作地点和工作性质,包括 REMOTE(远程工作)、INTERNS(实习生)和 VISA(签证)。一些公司提供全职、兼职和实习职位,同时也有一些公司提供雇佣地点是 ONSITE(办公地点)。每家公司只能发布一次招聘帖,不能由招聘公司或招聘网站发布。
帖子还提到了其他与招聘相关的话题帖子链接,以及一些在线招聘网站。值得一提的是,本帖还包含了用户对一些公司和他们的招聘信息的评论和回复。
HN 评论 381 comments | 作者:whoishiring | 10 hours ago #
https://news.ycombinator.com/item?id=40224213
-
- Zep AI 正在建立 LLM 应用堆栈的长期记忆层,招聘开发者倡导者,加速开发者采用并帮助塑造路线图。
-
- Internet Archive 正在寻找帮助构建网络爬虫、保存和公共访问服务的全职远程工程师。
-
- OneText 正在寻找领先的 UX 工程师,负责重新定义用户体验,包括结账流程和商家仪表板。
-
- Alchemy 是 Web3 的领先开发平台,正在招聘多个软件工程师角色,以及一些运营和营销职位。
-
- Sunnyside 正在寻找高级软件工程师,帮助打造出色的产品体验,专注于温和饮酒者社区的增长。
-
- LeagueApps 是一家青少年体育管理 SaaS 公司,正在招聘 Android 工程师、全栈工程师和商务发展代表等职位。
-
- Rune Labs 正在寻找 iOS 工程师,帮助帕金森病患者和临床医生更好地管理疾病。
-
- Medallion 正在寻找医疗技术产品经理,自动化提供者网络运营。
-
- StarTree 是一家云软件公司,正在招聘多个工程和销售职位,包括工程总监、软件工程师和企业架构师。
-
- Sentry.io 正在招聘软件工程师、工程经理和 SRE,提供 170,000 美元以上的薪酬。
-
- SerpApi 是领先的搜索引擎结果解析 API,正在招聘全栈工程师和客户成功工程师。
-
- Explo 是一家构建客户面板和分析的公司,正在招聘高级软件工程师。
-
- Silkline 正在寻找高级后端工程师,帮助解决采购问题。
-
- Felt 是创建地图和处理地理空间数据的最佳方式,正在招聘产品营销经理和销售工程师。
-
- ParaFi Technologies 正在招聘区块链基础设施工程师,帮助运行高性能区块链验证器和节点基础设施。
-
- FullContext.ai 正在招聘系统工程师、ML 工程师和前端工程师,帮助用户实时上下文和个人记忆提供行动和及时帮助。
-
- Modash.io 正在寻找高级产品工程师,帮助品牌和创作者通过数据驱动的影响力营销建立联系。
-
- Auros Global 是一家加密货币市场制造和高频交易公司,正在招聘策略开发人员、核心系统开发人员和交易所连接开发人员。
-
- Rescale Supply 正在寻找软件工程师,帮助解决食品制造行业的自动化和可扩展性问题。
-
- Houston Astros 正在寻找棒球研究分析师,负责支持教练开发小联盟球员和确定左外野手应该站在哪里。
Better and Faster Large Language Models via Multi-Token Prediction #
https://arxiv.org/abs/2404.19737
这篇文献的标题是《Better & Faster Large Language Models via Multi-token Prediction》,作者是 Fabian Gloeckle、Badr Youbi Idrissi、Baptiste Rozière、David Lopez-Paz 和 Gabriel Synnaeve。文献提出了一种改进的大型语言模型(LLMs)的训练方法,即通过多令牌预测(multi-token prediction)来提高样本效率和模型性能。具体来说,就是在训练语料库的每个位置时,让模型同时预测接下来的 n 个令牌,而不是传统的单令牌预测。
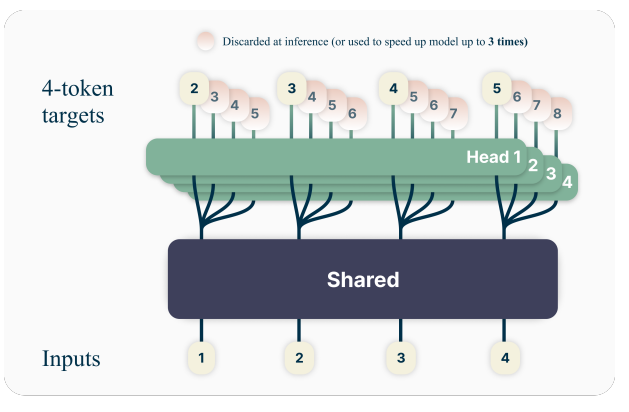
主要贡献和发现包括:
-
- 提出了一种简单的多令牌预测架构,该架构在训练时不增加时间或内存开销。
-
- 实验表明,这种训练范式在大规模模型中特别有益,例如,高达 13B 参数的模型平均能解决约 15% 的代码问题。
-
- 多令牌预测支持自推测解码(self-speculative decoding),使模型在多种批量大小下的推理速度提高了 3 倍。
-
- 多令牌预测在多轮训练中仍然保持优势,并且在自然语言模型上也显示出提升,尤其是在生成任务如摘要生成上,而不是基于多项选择问题和负对数似然的标准基准测试。
-
- 文献还探讨了多令牌预测如何通过减少训练时教师强制(teacher forcing)和推理时自回归生成(autoregressive generation)之间的分布差异来提高性能。
-
- 作者提出了未来工作的方向,包括如何自动选择多令牌预测损失中的 n,以及开发在嵌入空间中运行的改进辅助预测损失。
-
- 文献还讨论了多令牌预测对环境的影响,指出虽然这项工作可能减少训练 LLMs 的生态影响,但需要考虑使用这项工作可能带来的社会优势和风险。
这项研究的结果表明,多令牌预测是一种有效的方法,可以训练出更强大、更快的变换器(transformer)模型,并且对于大型模型尤其有益。作者希望这项工作能激发对 LLMs 的新型辅助损失的兴趣,以提高这些模型的性能、连贯性和推理能力。
HN 评论 114 comments | 作者:jasondavies | 16 hours ago #
https://news.ycombinator.com/item?id=40220851
评论中的观点归纳如下:
-
- 机器学习领域术语理解不清晰,文档信息不准确,领域内混乱普遍存在;
-
- 人工智能领域发展迅速,问题空间边界探索广泛,类似于早期物理学探索;3. 理解概念困难,但文档质量逐渐提高,高级工具文档如 LlamaIndex 有助于理解概念;
-
- YouTube 信息质量参差不齐,建议关注 3blue1brown 频道;
-
- AI 专家应关注未来技术发展,设计不同于 GPT-4 的产品;
-
- AI 在部署后是否继续训练存在讨论,用户与 AI 的互动对 AI 改进有帮助;
-
- 视频教程推荐:Andrej Karpathy 的“Lets build GPT-2”;
-
- 针对最新趋势,建议观看 3blue1brown 频道和 Yannic Kilcher 的视频;9. Llamaindex 文档质量被认为很差,难以理解术语和组织结构。
Figma OSS Alternative #
Penpot 是一款开源免费的设计软件,连接设计师和开发人员,实现无需繁琐交接流程的协作。Penpot 2.0 版本已发布,是一款基于 Web 的设计工具,弥合了设计师和开发人员之间的差距。

设计师和开发人员使用不同的工具时会导致困扰,设计师的视觉愿景可能会丢失,协作也会受到影响。而 Penpot 则可以让设计师确信他们的界面已经表达为代码,开发人员可以更快地实现设计。
Penpot 是一款功能强大的设计工具,支持界面设计、灵活的布局、设计系统、自定义字体、原型设计、交互流程、交互和过渡效果、反馈分享、规范、CSS、HTML/SVG 标记等。Penpot 表达设计时,可以原生地生成 CSS、SVG 和 HTML,让开发人员感觉就像在自己的界面中一样。团队可以享受一个无缝的工作流程,不再需要交接困扰。
Penpot 支持开放标准和开源,无论团队规模如何,您完全拥有自己的作品和工具。Penpot 还提供 API 和 Webhooks 的灵活性,让您可以将 Penpot 与现有的开发工具链集成。Penpot 得到了成千上万家各种规模的组织的青睐,包括许多知名的开源项目。
Penpot 还拥有一个强大的社区,提供图书馆、模板、贡献机会、教程等,让设计师和开发人员可以相互帮助和分享资源。
Penpot Fest 是一个设计师和开发人员汇聚一堂的会议,旨在构建无约束的合作关系。Penpot 是设计师和开发人员喜爱的工具之一,欢迎免费注册并体验。
HN 评论 89 comments | 作者:noashavit | 23 hours ago #
https://news.ycombinator.com/item?id=40218463
评论中的观点可以归纳为以下几种:
-
- 对专有设计工具的优势持肯定态度,认为开源软件无法与之竞争;
-
- 赞赏 Inkscape 等开源工具的功能和性能,认为它们已经变得非常出色;
-
- 提倡支持开源设计工具,认为公司和专业人士应该资助 FOSS 替代品的发展;
-
- 讨论 Figma 的性能和优化,有人认为其性能出色,也有人认为在某些情况下存在性能问题;
-
- 对 Figma 的功能和用户体验持不同看法,有人认为其功能出色,也有人认为在设计与开发之间的交接方面存在问题。
Car manufacturers break promise about sharing location data with police #
美国参议员 Ron Wyden 和 Markey 致函联邦贸易委员会,要求对主要汽车制造商进行调查,因其违反承诺保护客户的位置数据。汽车制造商曾承诺在向执法机构提供客户连接的汽车收集的位置数据之前,会坚持要求搜寻令或其他法庭命令。
然而,Wyden 的办公室的询问发现,只有通用汽车、福特、本田、Stellantis 和特斯拉要求执法机构出示搜寻令才会提供位置数据。而只有特斯拉会通知车主有关政府的要求。其他制造商如丰田、尼桑、斯巴鲁、大众、宝马等则确认会在收到传票时向美国政府机构披露位置数据,而传票并不需要法官批准。
这些回应直接违背了汽车行业公开承诺的内容,即只有在紧急情况下或车主同意的情况下,才会要求 “来自政府实体的地理位置信息请求或要求必须以搜寻令或法院命令的形式出现”。Wyden 和 Markey 警告称,未能保护美国人的隐私可能会带来危险后果,尤其是在最高法院做出的 Dobbs 裁决之后,允许各州对堕胎实施刑事化,并将其他生殖健康选择置于刑事化风险之中。
车辆位置数据可能透露一个人生活的亲密细节,包括那些跨州寻求护理的人、参加抗议活动的人、拜访心理或行为健康专业人士的人,或寻求药物滥用治疗的人。他们在信中敦促联邦贸易委员会调查这些汽车制造商的欺骗性声明以及他们有害的数据保留实践。
HN 评论 117 comments | 作者:skilled | 12 hours ago #
https://news.ycombinator.com/item?id=40222499
这篇帖子中的评论观点归纳如下:
- 一些汽车制造商未遵守承诺,只有少数几家需要法院批准才能向执法部门提供位置数据;
- 一些人认为车辆连接存在问题,可能会选择不连接的中国电动车;
- 有人认为中国政府保护隐私,与西方政府形成对比;
- 还有讨论关于维修汽车、消除车辆连接功能以及维护隐私的观点。
New findings point to an Earth-like environment on ancient Mars #
https://discover.lanl.gov/news/0501-ancient-mars/
一项利用 NASA “好奇号” 火星车上 ChemCam 仪器的研究团队在火星盖尔陨石坑内的湖床岩石中发现了高于平常水平的锰含量,这表明这些沉积物是在古代河流、三角洲或古代湖泊岸边形成的。这些结果今天发表在《地球物理研究杂志:行星版》上。

洛斯阿拉莫斯国家实验室空间科学与应用组的帕特里克・加斯达表示:“火星表面很难形成氧化锰,因此我们没有预期在湖岸沉积物中会发现如此高浓度的锰。在地球上,这类沉积物经常出现,因为我们大气中的高氧气体是光合生命和帮助催化锰氧化反应的微生物产生的。”
加斯达补充说:“在火星上,我们没有生命迹象,火星古代大气中产生氧气的机制也不清楚,因此锰氧化物是如何形成和富集在这里的真的很令人困惑。这些发现指向火星大气或地表水中发生了更大规模的过程,并显示需要更多工作来了解火星上的氧化过程。”
ChemCam 是在洛斯阿拉莫斯和法国国家航天局合作开发的,它使用激光在岩石表面形成等离子体,并收集该光以量化岩石中的元素组成。
受火星车探索的沉积岩是砂岩、粉砂岩和泥岩的混合物。砂岩更多孔,地下水可以更容易地穿过砂岩,与构成盖尔陨石坑大部分湖床岩石的泥岩相比。研究团队研究了锰如何富集在这些砂岩中 —— 例如,通过地下水通过湖岸或三角洲口的砂岩渗透 —— 以及哪种氧化剂可能导致锰在岩石中沉淀。
在地球上,锰因大气中的氧气而富集,这一过程通常会因微生物的存在而加速。地球上的微生物可以利用锰的多种氧化状态作为代谢能源;如果古代火星上存在生命,这些岩石中增加的锰量将是生命的有益能源来源。
ChemCam 仪器的首席调查员妮娜・兰扎说:“这些古代岩石揭示的盖尔湖环境让我们窥见一个看起来与今天地球上的某些地方惊人相似的可居住环境。锰矿物在地球上湖岸浅水中很常见,在古代火星上发现这样的可识别特征真是令人瞩目。”
论文:《盖尔陨石坑火星中锰富集的砂岩作为古代含氧湖水条件的指示物》《地球物理研究杂志:行星版》。
资助:NASA 喷气推进实验室
HN 评论 233 comments | 作者:geox | 10 hours ago #
https://news.ycombinator.com/item?id=40223457
评论中的观点归并如下:评论中提到了关于马斯克和盖茨的评论,以及关于冯·布劳恩的争议性观点,还有关于马尔斯生命起源的讨论,以及对科幻小说对科技发展的影响等。
StoryDiffusion: Long-range image and video generation #
https://storydiffusion.github.io/
本篇文章介绍了一种名为 StoryDiffusion 的方法,用于长距离图像和视频生成。该方法通过一种一致的自注意力机制实现了图像和视频的生成,在漫画生成和视频生成等领域展现出了出色的表现。

具体来说,StoryDiffusion 通过保持角色一致性来实现连贯的叙事,可以生成令人印象深刻的漫画。此外,通过图像语义运动预测器,结合生成的一致图像或用户输入图像作为条件,StoryDiffusion 还能生成高质量的视频。
在漫画角色生成方面,该方法可以创造出令人惊叹的一致性卡通角色图像,并且可以同时保持多个角色的 ID 并生成一致的图像。通过 StoryDiffusion 的一致自注意力机制,可以实现多角色连续叙事,生成出色的漫画作品。
HN 评论 62 comments | 作者:doodlesdev | 1 day ago #
https://news.ycombinator.com/item?id=40218021
评论中的观点归纳如下:
-
- 视频中存在细微的连续性错误,如服装按钮数目不一致、眼睛和头发变化、头部运动不流畅等;
-
- 视频生成技术的进步令人惊叹,与之前相比有了显著提升;
-
- 对视频中的不一致性表示担忧,认为生成视频模型需要更好的连续性支持;
-
- 对视频生成技术的潜在用途和影响提出担忧,认为可能会导致破坏和欺骗;
-
- 对生成视频中的语法错误表示关注,认为质量不一致;
-
- 对生成视频技术的发展速度表示担忧和惊讶,认为进展速度很快。
The Rabbit R1 is probably running Android and is powered by an Android app #
https://www.androidauthority.com/rabbit-r1-is-an-android-app-3438805/
本文介绍了 Rabbit R1,这是一款 AI 动力的手持设备,看起来在内部运行 Android 系统,并由一个 Android 应用程序提供支持。许多评论家批评类似 Rabbit R1 这样的 AI 设备的实用性,指出它们对智能手机的替代作用有限,实际上应该只是一个应用程序。

事实上,R1 的整个用户界面似乎都由一个 Android 应用程序管理。文章更新后,Rabbit 公司发表了一份声明,指出 R1 的界面不是一个应用程序,而是在云端运行的。他们解释说,他们使用的 LLM 在云端运行,这一点我们从未质疑过。他们还提到,Rabbit OS 和 LAM 经过了定制化处理,专为 R1 设计,不支持第三方客户端。他们警告用户避免使用盗版的 Rabbit OS 应用程序,因为这些应用可能会窃取用户数据。
文章还提到,一些 AI 设备似乎在 Android 系统的基础上运行,用户与之互动的整个界面由一个单一的 Android 应用程序提供支持。作者通过安装 Rabbit R1 的启动器 APK 到一个 Pixel 6a 手机中,成功模拟了 Rabbit R1 的体验。尽管一些功能可能无法正常工作,但这一实验证明了很多这类小众硬件产品的核心其实是基于修改过的 AOSP 运行的。
HN 评论 223 comments | 作者:gmjosack | 1 day ago #
https://news.ycombinator.com/item?id=40217453
评论中的观点大致可以归纳为以下几点:
-
- 一些人认为 Rabbit R1 可能只是在运行 Android,并由 Android 应用程序提供动力,认为这种设计并不愚蠢,但也指出硬件的特定功能才是产品的关键所在;
-
- 一些人对当今技术的发展感到厌倦,认为现在的技术发展主要是小幅度规格提升,缺乏真正解决人们实际问题的创新;3. 有人认为需要等待基础技术的进步,如 AR、机器人技术、自动驾驶等成熟后,才会出现更有趣的产品;
-
- 也有人对 Rabbit R1 的激光显示器表示赞赏,但认为软件限制了其潜力;
-
- 一些人对 Rabbit R1 的亮度在明亮环境下表现不佳以及激光束无法映射到不平整表面表示怀疑;
-
- 还有人对 Rabbit 的创始人的背景和公司的商业模式提出质疑,认为需要真正的创新和民主定价。
Run llama3 locally with 1M token context #
https://ollama.com/library/llama3-gradient
本文介绍了 LLama-3 梯度模型,该模型将 LLama-3 8B 的上下文长度从 8k 扩展到超过 1m 个标记。该模型基于 Meta Llama 3,使用 Meta Llama 3 社区许可协议进行许可。许可协议授予用户对 LLama 材料的使用、复制、分发、创建衍生作品和修改的有限许可。

用户在使用 LLama 材料时需遵守适用法律和法规,并遵守 LLama 材料的可接受使用政策。如果用户的产品或服务的月活跃用户超过 700 万,则需要向 Meta 申请许可。用户不得将 LLama 材料用于改进其他大型语言模型,除非得到 Meta 明确授权。
协议还包括知识产权、责任限制、条款和终止等方面的内容。如有违反协议或发现问题,用户可通过指定方式举报。
HN 评论 71 comments | 作者:mritchie712 | 1 day ago #
https://news.ycombinator.com/item?id=40215767
评论中的观点归纳如下:
Gemini 1.5 使用 1M 令牌进行训练,改变了游戏规则;
运行大上下文时延迟可能较高;
硬件需求对于本地运行很重要,可能需要高端工作站或服务器;
大上下文长度提供更多信息但不一定解锁智能;
大上下文窗口可能导致幻觉或不完美回忆;
硬件需求取决于上下文窗口大小,可能需要大量 RAM 和强大 CPU/GPU;
In-Context Learning 可以实现持续学习;大上下文窗口需要每次请求重新加载和处理上下文信息。