Big media publishers are inundating the web with subpar product recommendations #
https://housefresh.com/david-vs-digital-goliaths/

这篇文章主要讨论了谷歌如何影响独立网站,以及为什么您不应该信任在谷歌搜索结果排名靠前的大型媒体出版商的产品评论。文章指出大型媒体出版商通常在没有亲自测试的情况下推荐产品,并简单地转述营销材料和亚马逊上的信息。同时,文章还提到了谷歌的产品评论更新如何影响这些结果,以及一些大型媒体出版商如何利用 SEO 策略来欺骗谷歌。
文章还列举了一些大型媒体出版商在产品推荐方面的不诚实做法,以及他们如何利用自己的权威性和公众对其品牌的信任来销售各种产品。最后,文章呼吁谷歌应该对所有网站都应用高质量评论的标准,而不是偏袒大型媒体出版商。
HN 评论 330 comments | 作者:beavershaw | 1 day ago #
https://news.ycombinator.com/item?id=39433451
根据提供的链接内容,这篇帖子中的评论观点可以归纳为:
有人认为 Google 对产品评论进行干预是正确的,因为这有助于提高评论质量,但也指出大型媒体公司找到了规避规则的漏洞。
有人认为 Google 偏向大型媒体网站,导致小型独立网站难以获得高排名。
有人指出大品牌网站在排名上更容易,而个人开发者则面临更多挑战。
有人创建了自己的搜索引擎来过滤 SEO 垃圾并公开使用。
有人对 Google 搜索结果的质量表示不满,转而使用 Bing 等搜索引擎。
有人讨论了搜索引擎的付费模式,认为付费搜索引擎可能是一个解决方案。
In Defense of Simple Architectures (2022) #
https://danluu.com/simple-architectures/
《简单架构的辩护》
作者介绍了 Wave 公司,一个价值 17 亿美元、拥有 70 名工程师的公司,他们的产品是一个执行加减操作的 CRUD 应用程序。该公司的架构是一个标准的 CRUD 应用程序架构,使用 Python 单体架构在 Postgres 数据库上运行。
简单架构的有效性: 作者强调了简单架构的有效性,指出大多数媒体关注复杂架构,而忽略了简单架构的优势。他提到了在技术会议上关于复杂微服务架构的演讲数量远多于关于构建简单单体架构的演讲数量。
技术选择: 作者讨论了一些技术选择,如使用同步的 Python、使用队列处理长时间运行的任务、在本地数据中心部署等。他还提到了一些技术选择的利弊,如使用 RabbitMQ、Celery、SQLAlchemy 和 Python。
满意的选择: 作者分享了一些他们对技术选择感到满意的领域,如使用 GraphQL、HTTP/3 替代自定义传输协议以及使用 Kubernetes 进行主机管理。
不可避免的复杂性: 作者提到了一些不可避免的复杂性,比如与电信集成相关的挑战,以及在扩展到新市场时必须遵守的本地数据存储法规。
总结: 通过保持应用程序架构尽可能简单,作者认为他们可以将复杂性和人员编制预算用于那些对业务有益的复杂性。这种简单的方法使他们能够在非常少的工程师的情况下建立一个相当大的业务。
HN 评论 372 comments | 作者:Brajeshwar | 12 hours ago #
https://news.ycombinator.com/item?id=39440179
根据您提供的链接,这篇帖子中的评论观点可以归纳为:
Microservices 并非性能策略,而是潜在的成本节约策略和工程协调策略。
对于大多数公司来说,工程协调是 Microservices 带来的最实际好处,因为可以让一个团队负责一个代码库,保持整洁。
微服务架构对于团队规模扩展更有帮助,但对于绝大多数用例来说,微服务是错误的转变。
微服务架构增加了复杂性,但可以降低关键故障的数量。
微服务架构更多是一种组织策略,需要组织基础才能正确实施。
将共享的单体架构拆分成多个内部库和模块可以提高所有权。
微服务架构可以帮助性能,例如将性能关键部分拆分出来并使用不同的堆栈或语言。
从一开始使用微服务架构会增加复杂性,最好在性能问题出现后再拆分部分服务。
以上是对帖子评论观点的归纳总结。
My productivity app is a never-ending .txt file (2022) #
https://jeffhuang.com/productivity_text_file/
这篇文章介绍了作者 Jeff Huang 在过去 14 年中使用单个.txt 文件作为他的主要生产力系统的经验。文章中提到,作者尝试过各种待办事项列表、任务跟踪器和生产力应用,但最终放弃了,转而使用单个文本文件来记录待办事项。他每天晚上会将第二天日历上的所有事项添加到文本文件的末尾,作为每日待办事项清单。这个文件包含了安排的任务、差事和工作项目,并让他思考是否安排了一天的合适工作量。作者还提到,这个文本文件同时也是他的记录,包括会议记录、研究笔记等,使得他能够回顾过去的工作和完成的任务。
作者还介绍了他的工作流程,包括使用日历、电子邮件处理、每日待办事项清单的制作和记录,以及如何在一天结束时进行快速回顾。他强调了这种系统的几个优点,如帮助他在每天醒来时立即知道要做什么、避免记忆负担、轻松回顾过去的工作和避免无休止的待办事项列表。
此外,作者还提到了他使用的一些快捷方式和功能,如一致的写作风格、标签和搜索功能。他还分享了关于电子邮件处理的简单标记系统,以及如何在结束一天时进行快速回顾和准备第二天的待办事项清单。
总的来说,这篇文章详细介绍了作者使用单个文本文件作为生产力工具的经验,以及他的工作流程和一些技巧。这种简单而高效的方法帮助作者管理工作和任务,同时保持高效和组织。
如果需要查看更多详细信息,可以访问原文链接。
HN 评论 255 comments | 作者:yarapavan | 1 day ago #
https://news.ycombinator.com/item?id=39432876
根据您提供的链接,评论中的观点可以总结为:
许多人分享了他们使用文本文件进行任务管理的经验,包括使用 TODO.TXT 文件和类似的方法。
一些人提到了他们使用的不同工具,如 Emacs org mode、Obsidian 等,以及它们的优点和局限性。
有人讨论了如何有效管理任务上下文,以及开发适合自己工作流程的工具。
一些人分享了他们使用的笔记和计划工具,如 Obsidian、Bear 等,以及它们的优势和劣势。
有人提到了使用 Git 来管理任务列表的好处,包括版本控制和备份。
一些人分享了他们使用纸质笔记的经验,以及纸质笔记在某些情况下的优势。
有人讨论了使用 Obsidian 等工具的体验,包括速度、定制性等方面的观点。
一些人分享了他们使用 Markdown 格式的纯文本笔记的方式,以及如何将它们同步到 GitHub 等平台。
这些观点涵盖了关于任务管理、笔记工具和工作流程优化的多个方面。每个人都有自己独特的偏好和经验,选择适合自己的工具和方法是关键。
I broke IKEA (2023) #
https://cohost.org/sirocyl/post/2891449-i-broke-ikea
这篇文章讲述了作者在接到 IKEA 关于货物送货的电话时,误将其当作垃圾电话而进行了一系列按键操作,导致电话系统崩溃的故事。
作者的手机设有一种防垃圾电话的功能,通过按键来筛选电话的真实性。当 IKEA 打来电话要求按 1 以继续通话时,作者误以为是垃圾电话,迅速按下了错误按键,导致电话系统发生故障。电话内容提及了货物送达时间和联系方式,但最终只有杂音和系统故障声音。
作者调侃自己应该买 60 只蓝鲨鱼玩具,而不是遭遇这次电话系统崩溃的尴尬。文章以录音和文字的形式呈现了整个通话过程,让人感受到作者在意外中的无奈和幽默。
HN 评论 53 comments | 作者:jcurbo | 24 hours ago #
https://news.ycombinator.com/item?id=39436358
有人分享了一个关于 Psion Series 5 的故事,讲述了如何利用长电话号码进入多个电话答录机。
有人提到在国际电话通话时,利用默认设置的电话答录机进行欺诈。
有人讨论了通过电话答录机接受来电收费的情况。
有人分享了 Rupert Murdoch 在 90 年代末和 00 年代初进行的类似行为。
有人讨论了音频转录的准确性和技术细节。
有人猜测音频中可能隐藏着密码等信息。
有人提出尝试解码音频中的内容。
有人讨论了音频中可能存在的二进制数据。
有人解释了音频中的声音可能是由于 PC 崩溃导致的电磁干扰。
有人讨论了网站加载问题和第三方内容屏蔽的情况。
有人分享了关于 Asterisk 脚本生成音频的信息。
有人讨论了自动化应对垃圾电话的方法。
有人分享了一些有趣的电话服务。
有人讨论了音频中的二进制流。
有人分享了对音频的解码想法。
有人讨论了法律风险和道德责任。
有人分享了社交媒体评论分析工具和其重要性。
这些观点涵盖了帖子中的不同主题和讨论,展示了读者对话题的多样看法和兴趣点。
Jeff Dean: Trends in Machine Learning [video] #
https://www.youtube.com/watch?v=oSCRZkSQ1CE

摘要:在本次演讲中,我将重点介绍人工智能和机器学习领域的几个令人兴奋的趋势。 通过结合改进的算法和 ML 专用硬件的重大效率改进,我们现在能够构建比以往任何时候都更强大的通用机器学习系统。 作为一个例子,我将概述 Gemini 系列多模式模型及其功能。 这些新模型和方法对于将机器学习应用于世界上的许多问题具有重大影响,我将重点介绍其中在科学、工程和健康领域的一些应用。 本次演讲将介绍谷歌许多人所做的工作。
简介:Jeff Dean 于 1999 年加入 Google,现在担任 Google 首席科学家,专注于 Google DeepMind 和 Google Research 的人工智能进展。 他关注的领域包括机器学习和人工智能,以及人工智能在解决问题上的应用,以对社会有益的方式帮助数十亿人。 他的工作已经成为谷歌多代搜索引擎、最初的广告服务系统、BigTable 和 MapReduce 等分布式计算基础设施、Tensorflow 开源机器学习系统以及许多库和开发人员工具不可或缺的一部分。
杰夫获得了博士学位。 华盛顿大学计算机科学学士学位和理学士学位 明尼苏达大学计算机科学与经济学博士学位。 他是美国国家工程院院士、美国艺术与科学院院士、计算机协会 (ACM) 院士、美国科学促进会 (AAAS) 院士,以及 2012 年 ACM 计算奖和 2021 年 IEEE 约翰·冯·诺依曼奖章。
赞助商:肯尼迪研究所
HN 评论 119 comments | 作者:belter | 1 day ago #
https://news.ycombinator.com/item?id=39435320
根据提供的链接内容,这篇帖子中的评论观点主要包括:
有人认为谷歌的演讲内容主要是在阅读由谷歌营销团队创建的幻灯片,感觉不够完整。
有人认为谷歌在机器学习方面取得的研究突破,所以谷歌的做法并不令人意外。
也有人指出 OpenAI 发明了 RLHF,而 DPO 是在斯坦福发明的。
有人提到谷歌在培训基础设施方面提供了帮助。
有人批评机器学习社区的论文变成了广告,认为不应该破坏审查系统。
有人认为多模态研究和最新的神经符号重组并不是为了推动我们对当前能力的理解,而是为了维持现状。
有人讨论了 AI 摘要工具的使用,认为学习如何有效摘要可能会节省大量时间并改善决策。
以上是对帖子中评论观点的归纳总结。
SSDs have become fast, except in the cloud #
http://databasearchitects.blogspot.com/2024/02/ssds-have-become-ridiculously-fast.html
在最近几年中,基于闪存的固态硬盘(SSDs)在大多数存储用途中大量取代了传统磁盘。每个 SSD 内部包含许多独立的闪存芯片,每个芯片可以并行访问。假设 SSD 控制器跟得上,SSD 的吞吐量主要取决于与主机的接口速度。在过去的六年中,我们看到从 SATA 到 PCIe 3.0 再到 PCIe 4.0 再到 PCIe 5.0 的快速过渡。因此,SSD 的吞吐量爆炸性增长。同时,我们不仅看到了更好的性能,还看到了每美元的更多容量。顶级 PCIe 5.0 数据中心 SSDs(如 Kioxia CM7-R 或 Samsung PM1743)实现了高达 13 GB/s 的读取吞吐量和 2.7M+ 的随机读取 IOPS。现代服务器大约有 100 个 PCIe 通道,这使得在单个服务器中拥有数十个 SSDs(每个通常使用 4 个通道)以全带宽运行成为可能。例如,在我们的实验室中,我们有一台单插槽 Zen 4 服务器,配备了 8 个 Kioxia CM7-R SSDs,实现了 100GB/s 的 I/O 带宽。
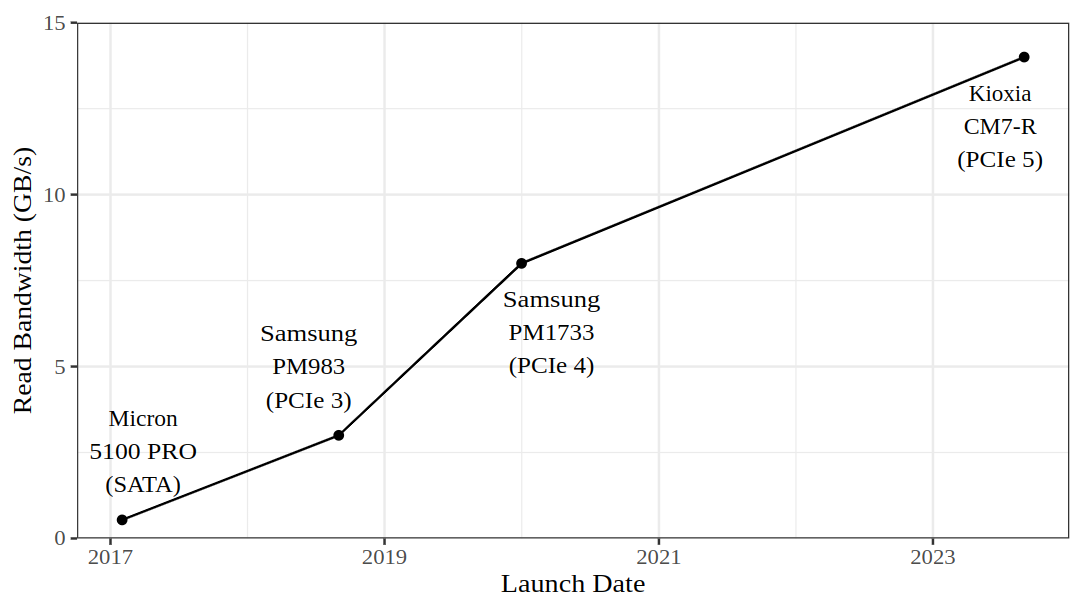
AWS EC2 是早期的 NVMe 先驱,于 2017 年初推出了带有 8 个物理连接的 NVMe SSDs 的 i3 实例。当时,NVMe SSDs 仍然很昂贵,一台服务器中有 8 个是非常了不起的。每个 SSD 的读取(2 GB/s)和写入(1 GB/s)性能也被认为是最先进的。2019 年,随着 i3en 实例的推出,存储容量每美元翻了一番。自那时以来,推出了几种 NVMe 实例类型,包括 i4i 和 im4gn。然而,令人惊讶的是,性能并没有提高;在 i3 推出七年后,我们仍然困在每个 SSD 2 GB/s 的速度上。事实上,备受尊敬的 i3 和 i3en 实例仍然是 EC2 在 IO/$和SSD容量/$方面提供的最佳选择。在当前阶段,现代 SSDs 与主要云供应商提供的 SSDs 之间的性能差距,尤其是在读取吞吐量、写入吞吐量和 IOPS 方面,接近一个数量级。
HN 评论 247 comments | 作者:greghn | 7 hours ago #
https://news.ycombinator.com/item?id=39443679
这篇评论讨论了云端 SSD 的性能问题,其中提到 SSDs 在云中通过网络连接,这导致其性能远远不及本地 SSD。
评论中指出 AWS 实例类型中的 SSD 是 “物理连接” 到主机的,并非 SSD 支持的 NAS 解决方案。
评论还指出,SSDs 的性能比数据中心网络慢两个数量级。
此外,有关 “本地” SSD 实际上并非物理连接,而是通过网络协议进行传输的观点也引起了争议。
有人认为 AWS 的 “实例存储” 确实是物理连接到主机的存储设备,而非通过网络连接。
对于此观点,云提供商之间可能存在差异,有的提供的本地 SSD 确实是物理连接,而有的可能不是。
评论还提到了云供应商可能选择将 SSD 连接到网络而非物理主机的原因,以支持实例迁移等功能。
最后,一些用户讨论了他们在云端运行 Clickhouse 数据库时遇到的数据迁移和性能问题。
Microsoft is spying on users of its AI tools #
https://www.schneier.com/blog/archives/2024/02/microsoft-is-spying-on-users-of-its-ai-tools.html
2024 年 2 月 20 日,Bruce Schneier 在他的博客上发布了一篇文章,标题为“Microsoft Is Spying on Users of Its AI Tools”。文章指出,Microsoft 宣布发现中国、俄罗斯和伊朗黑客正在使用其人工智能工具,据推测是编码工具,以提高其黑客能力。
根据报告,Microsoft 与 OpenAI 合作,分享了检测到的与国家关联的对手 Forest Blizzard、Emerald Sleet、Crimson Sandstorm、Charcoal Typhoon 和 Salmon Typhoon 使用 LLMs 来增强网络操作的威胁情报。文章指出,Microsoft 或 OpenAI 之所以知道这一点,只能是通过监听聊天机器人会话。作者认为,虽然这并不令人惊讶,但这一点得到了证实,即 Microsoft 和 OpenAI(以及可能是其他人)正在监视我们对人工智能的使用。
文章中还包含了读者的评论,其中有人指出 OpenAI 正在“监视”ChatGPT 会话,类似于电子邮件提供商“监视”您的电子邮件以过滤垃圾邮件。另一位评论者提到,AI 培训正在从网站中提取信息,如果能够检测到这种情况,就可以将网络爬虫重定向到从/dev/random 生成 Vogon 诗歌的 CGI。还有评论者讨论了关于 AI 的更大问题,包括谁来构建、谁来使用以及如何使用 AI。
HN 评论 134 comments | 作者:mikece | 8 hours ago #
https://news.ycombinator.com/item?id=39442429
根据提供的链接内容,对帖子评论的观点进行中文摘要如下:
微软和其他公司在使用 AI 工具时会监视用户,这并不令人惊讶,因为这是互联网运作的方式。
大多数在线公司都是数据挖掘者,用户在这些服务上的所有操作都会被用来改进服务。
用户使用现代微软产品时会向他们发送大量数据。
如果你在使用这些工具,就等于允许他们收集你的所有数据。
本质上,“每个人都在监视用户,这是互联网运作的方式”。
用户应该明确并可撤销地允许这些公司查看聊天对话。
在互联网上有很多隐私侵犯的例子,但这个特定的行为对我来说似乎没问题。
微软应该阻止人们使用这些工具来帮助他们构建恶意软件。
评论在社交媒体上是衡量用户参与度以及对品牌、产品和内容看法的重要方式。
用户评论可以显示对品牌或内容的兴趣和价值认可。
在社交媒体上增加评论数量的方法可能包括在发布的内容中包含开放式问题的号召行动。
评论在内容如何根据排序算法显示给用户方面起着重要作用。
以上是对帖子评论观点的中文摘要。
Web Scraping in Python – The Complete Guide #
https://proxiesapi.com/articles/web-scraping-in-python-the-complete-guide
根据提供的链接内容,这篇文章是关于使用 Python 进行网页抓取的完整指南。文章介绍了使用 Python 进行网页抓取的优势、最佳 Python 网页抓取库(如 BeautifulSoup、Scrapy、Selenium 等)、先决条件、选择目标网站、编写抓取代码、下载页面、使用选择器提取数据、处理动态内容、处理网站阻止、处理速率限制、旋转用户代理等内容。
HN 评论 122 comments | 作者:anticlickwise | 8 hours ago #
https://news.ycombinator.com/item?id=39442273
有关网页爬虫的评论中,观点主要包括分离爬取和抓取步骤、本地缓存网页以避免重复下载、使用 requests-cache 库来实现本地缓存、通过 Urlbox 进行网页渲染和保存到 S3 桶、将 ETL 步骤分离以便测试和验证、ELT 模型更适合大多数用例、使用 AWS、Node 和 Snowflake 构建 ETL 管道等。
WebKit switching to Skia for 2d graphics rendering #
https://blogs.igalia.com/carlosgc/2024/02/19/webkit-switching-to-skia-for-2d-graphics-rendering/
在这篇博文中,作者介绍了 WebKit 正在将 2D 图形渲染切换到 Skia 的过程。过去几年,他们一直在努力改进 WebKit GTK 和 WPE 端口的图形性能,推出了一些功能,如线程渲染、DMA-BUF 渲染器和垂直重绘同步(VSync)。尽管这些改进有助于保持 WebKit 的竞争力,甚至在某些情况下表现优于其他引擎,但很明显他们已经达到了基于 CPU 的 2D 渲染器的极限。
他们尝试过让 Cairo 支持 GPU 渲染,但由于该库设计围绕基于 PostScript 模型的有状态操作,导致 GPU 渲染效果不佳。与此同时,其他网络引擎将更多工作转移到 GPU,包括 2D 渲染,许多操作速度更快。
经过调查所有可用的 2D 渲染库,他们决定尝试编写自己的库。最终他们选择了 Skia,因为 Skia 提供了 API 稳定性,可以像大多数依赖项一样打包使用。他们内部尝试了 Skia,并取得了令人印象深刻的性能结果。最终他们决定采用 Skia,这将带来性能改进,简化代码并允许实现新功能。
作者还提到他们已经准备好将 Skia 整合到 WebKit 中,并计划改变架构以更有效地支持 GPU 渲染。他们将继续在 Skia 实现上工作,并计划在未来支持 GTK 等其他端口。
HN 评论 163 comments | 作者:jessevdk | 16 hours ago #
https://news.ycombinator.com/item?id=39438908
根据您提供的链接,这篇帖子中的评论观点可以归纳为:Skia 构建过程繁琐,但性能和功能优秀;Blend2D 是一个更易构建的替代选择;Cairo 处于维护模式,不再被广泛开发;Impeller 被认为不如 Skia 和 Flutter;对于 2D 渲染,Blend2D 和 Skia 是活跃开发的两个选择。
Translating OpenStreetMap data to HTML5 Canvas with Rust and WebAssembly #
https://mary.codes/blog/programming/translating_openstreetmaps_to_HTML5_canvas_rust_wasm/
这篇博文由 Mary Knize 撰写,主要介绍了如何使用 Overpass API 读取 OpenStreetMap 数据,通过 Rust 进行数据解析,然后将地图绘制到 HTML5 画布上。

Mary Knize 正在对名为 Line Buddy 的旧项目进行改进,该项目使用了一个现已弃用的 API 库和 A-Frame 来以 3D 形式可视化迪士尼世界主题公园的等待时间。
原始项目使用 OpenStreetMap 的截图作为基础,其中列代表等待时间,但由于 API 版本不再可用,所有等待时间都为零。作者计划使用 OpenStreetMap 数据创建地图的简化版本,最终将创建 3D 地图,但首先作为概念验证,将绘制到 HTML5 画布上。
HN 评论 32 comments | 作者:todsacerdoti | 13 hours ago #
https://news.ycombinator.com/item?id=39439655
根据您提供的链接,对帖子中评论的观点进行中文摘要:
有评论者认为文章清晰、逐步,适合有经验的程序员,感谢作者的分享。
有人指出直接从地理坐标绘图可能导致视觉失真,建议重新投影数据以确保准确性。
有人认为在 OpenStreetMap 基础上绘制不会有太大问题,但绘制圆形等图形时可能会出现问题。
有人讨论了地图投影的选择对视觉效果的影响,提到了 Mercator 投影的优点。
有人讨论了 Google Maps 在网页上使用的投影方式。
有人提到了使用 N-vector 表示法来解决纬度引起的失真问题。
有人分享了对 Overpass API 的使用建议。
有人讨论了使用 Rust 和 WebAssembly 处理大量坐标数据的优势。
有人提出了使用 Mapsforge 二进制格式的建议。
有人讨论了 Rust 和 JavaScript 在数据处理速度上的比较。
有人提出了关于实时预测等功能的建议。
有人分享了自己在 Android 上使用 Canvas 绘制图表的经历。
有人讨论了使用 WebGL 着色器进行绘制的优势。
有人提到了使用 SVG 的替代方案。
有人建议使用 Mapsforge 二进制格式来减少带宽使用。
有人讨论了 Rust 和 JavaScript 在数据处理速度上的差异。
希望这个总结能帮助您了解帖子中的不同观点!